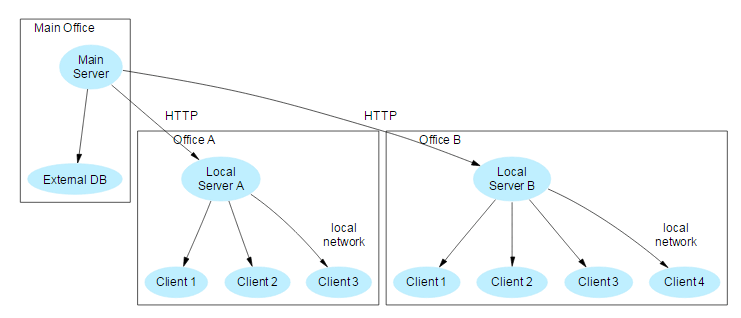
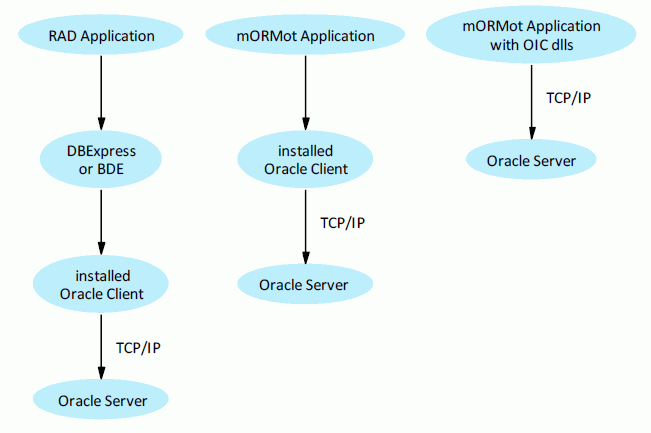
After having tested and enhanced the external database
speed (including BATCH mode), we are now able to benchmark all
database engines available in mORMot.
In fact, the ORM part of our framework has several potential database
backends, in addition to the default SQLite3 file-based engine.
Each engine may have its own purpose, according to the application
expectation.
The following tables try to sum up all available possibilities, and give
some benchmark (average rows/seconds for writing or read).
In these tables:
- 'internal' means use of the internal SQLite3 engine;
- 'external' stands for an external access via
SynDB;
- '
TObjectList' indicates a
TSQLRestServerStaticInMemory instance either static (with no
SQL support) or virtual (i.e. SQL featured via SQLite3 virtual table
mechanism) which may persist the data on disk as JSON or compressed
binary;
- 'trans' stands for Transaction, i.e. when the write process is nested
within
BeginTransaction / Commit calls;
- 'batch' mode will be described in this
article;
- 'read one' states that one object is read per call (ORM generates a
SELECT * FROM table WHERE ID=?);
- 'read all' is when all 5000 objects are read in a single call (i.e. running
SELECT * FROM table);
ACID is an acronym for "Atomicity Consistency Isolation
Durability" properties, which guarantee that database transactions are
processed reliably: for instance, in case of a power loss or hardware failure,
the data will be saved on disk in a consistent way, with no potential loss of
data.
In short: depending on the database you can persist up to 150,000 objects per
second, or retrieve 240,000 objects per second.
With a high-performance database like
Oracle and our
direct
access classes, you write 53,000 and read 72,000 objects per second.
Difficult to find a faster ORM, I suspect. :)