
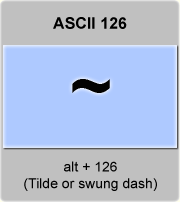
It was reported on our forum that some web server had issues with this tilde character, when using our UrlEncode() function.
Our framework code just follows the RFC 3986 official recommendations since years:
2.3. Unreserved Characters
Characters that are allowed in a URI but do not have a reserved purpose are called unreserved. These include uppercase and lowercase letters, decimal digits, hyphen, period, underscore, and tilde.
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
This was our reference material - as quoted in the source code.
The problem is that this RFC 3986 from 2005 - 15 years ago! - is not known and applied.
Most code in the wild still follows the old RFC 1738 from 1994 - from 26 years ago. An eternity in the scale of the Internet.
So it is clearly a mess...
After some search on the Internet, an explicit blog article seems to argue - with good background - that the tilde should be encoded, whatever the "new" RFC states... Just for the sake of systems and humans usability.
Our concern is that some users and code will expect "~" to be escaped... We are afraid that it may break existing code. It will break some of our regression tests for sure. And we don't like breaking things.
We should eventually perform this background incompatible change, and follow RFC 1738 by escaping the "tilde" character, to ease compatibility with most existing servers in the wild. This blog article is to notify "mORMot" users of this upcoming change, and have your feedback before including this modification.
