
A lot of our code, and probably yours, is highly relying on text
process.
In our mORMot framework, most of its features use JSON
text, encoded as UTF-8.
Profiling shows that a lot of time is spent computing the end of a text buffer,
or comparing text content.
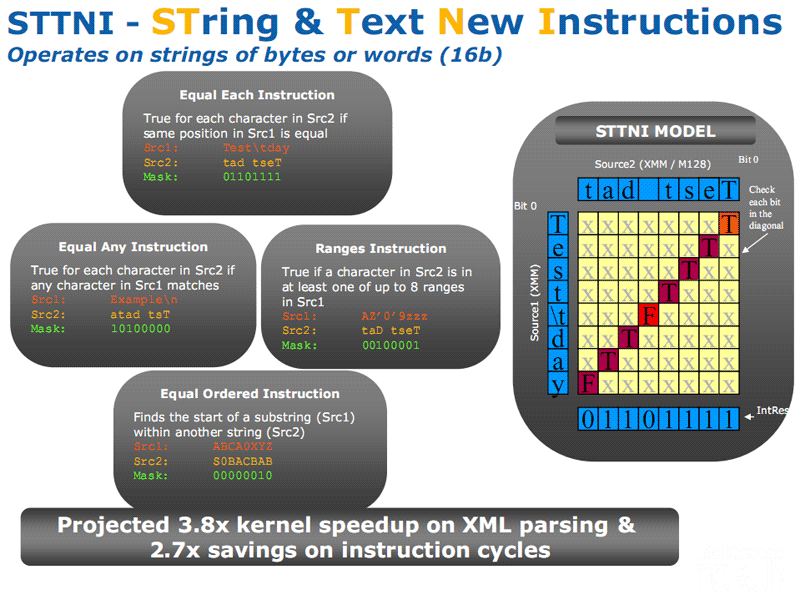
You may know that In its SSE4.2 feature set, Intel added STTNI (String
and Text New Instructions) opcodes.
They are several new instructions that perform character searches and
comparison on two operands of 16 bytes at a time.
I've just committed optimized version of StrComp()
and StrLen(), also used for our
TDynArrayHashed wrapper.
The patch works from Delphi 5 up to XE8, and with FPC - unknown SSE4.2 opcodes
have been entered as hexadecimal bytes, for compatibility with the last century
compilers!
The resulting speed up may be worth it!
Next logical step would be to use those instruction in the JSON process
itself.
It may speed up the parsing speed of our core functions (which is already very
optimized, but written in a classical one-char-at-a-time reading).
Main benefit would be to read the incoming UTF-8 text buffer by blocks of 16
bytes, and performing several characters comparison in a few CPU cycles, with
no branching.
Also JSON writing would benefit for it, since escaping could be speed up thanks
to STTNI instructions.
Any feedback is welcome, as usual!
